
HF Patient Survival Classification.
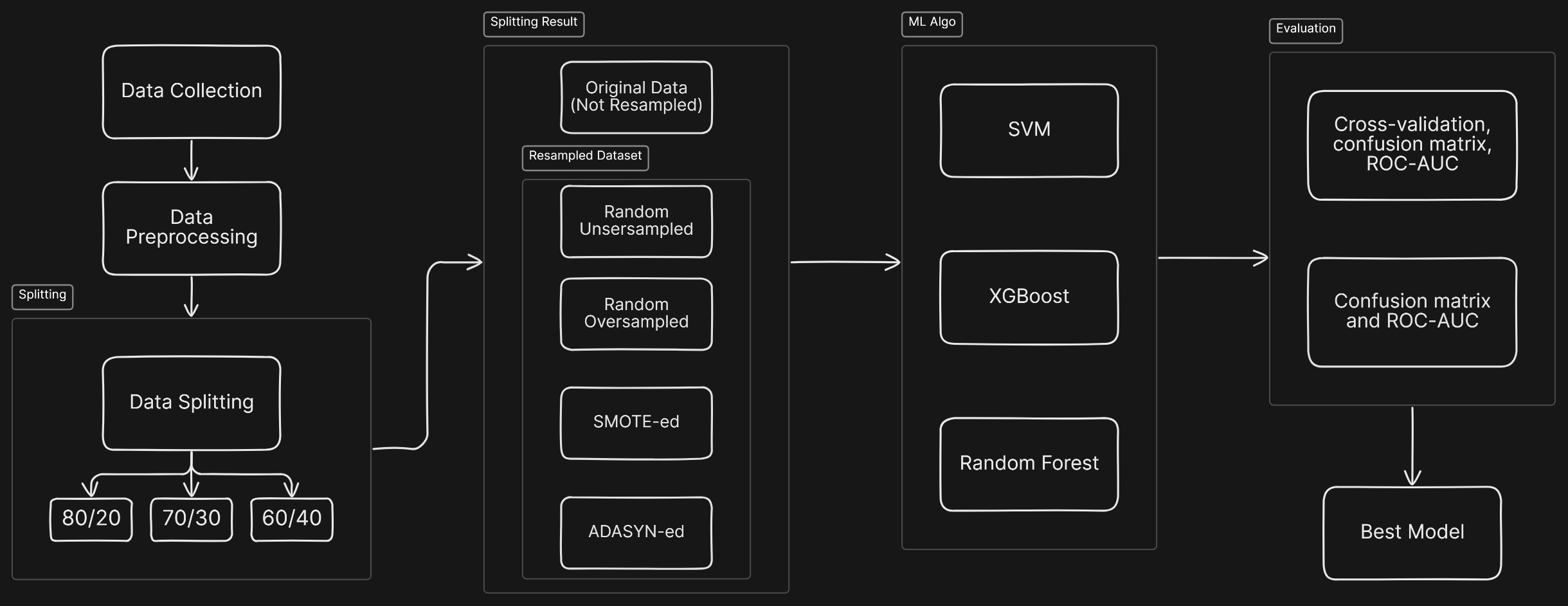
Inspired by Davide Chicco & Giuseppe Jurman’s research, my thesis project focused on improving the performance of ML models in predicting patient survival. For this project, I used two datasets. The first one is Chicco & Jurman’s original dataset found on Kaggle. This dataset is called SOLE DATASET.
The second dataset was retrieved from Zhang et al. on PhysioNet. The second dataset was then combined with Chicco & Jurman’s dataset, producing a second dataset called COMBINED DATASET.
Both SOLE and COMBINED dataset were divided into 3 splits, 60/40, 70/30, and 80/20. Each split was used in 5 different way. 1 without resampling, and 4 with resampling (RUS, ROS,SMOTE, ADASYN). Each dataset was then be used with SVM, XGBoost, and Random Forest algorithms, and evaluated with 2 evaluation types:
- With Cross Validation
- Without Cross Validation
With all these different configurations, the best model is achieved with XGBoost. It used 70/30 split of the SOLE DATASET with no resampling, used CrossVal, and achieved 91.11% accuracy, 87.50% recall, and 93.99% AUC.